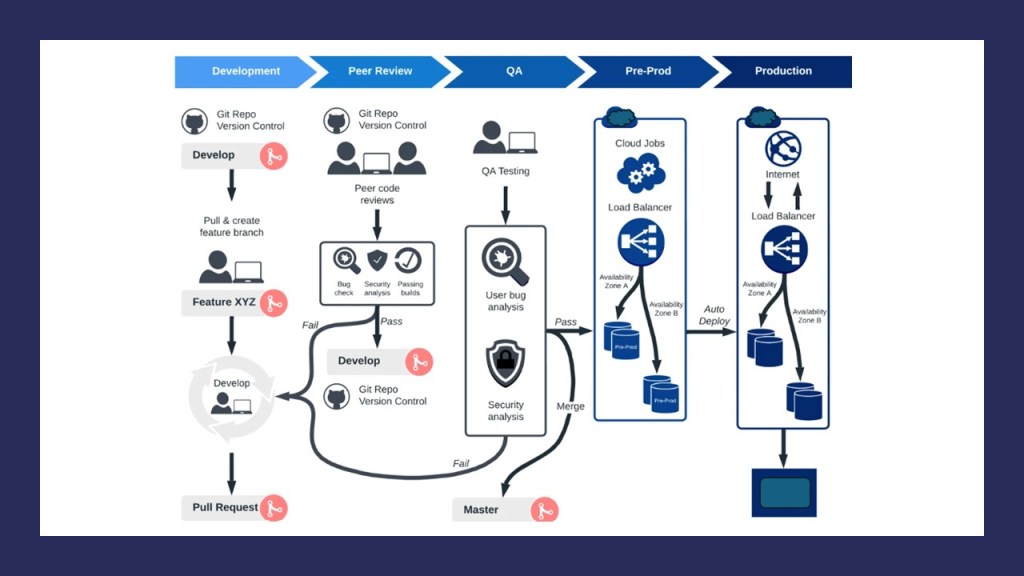
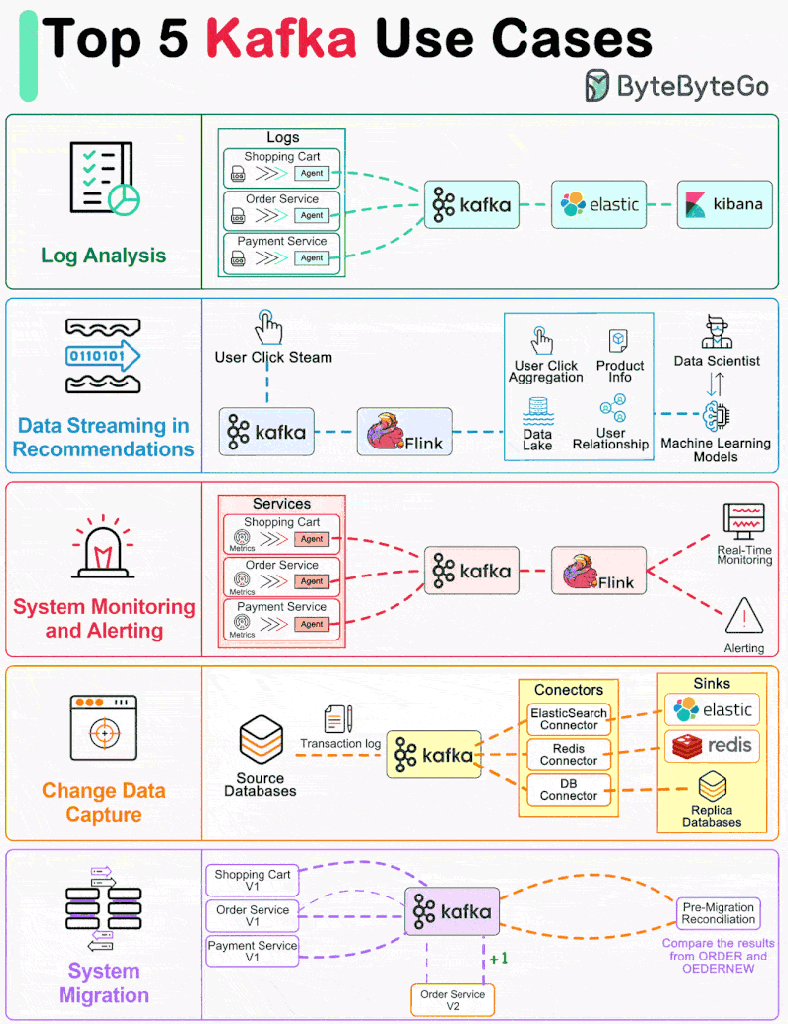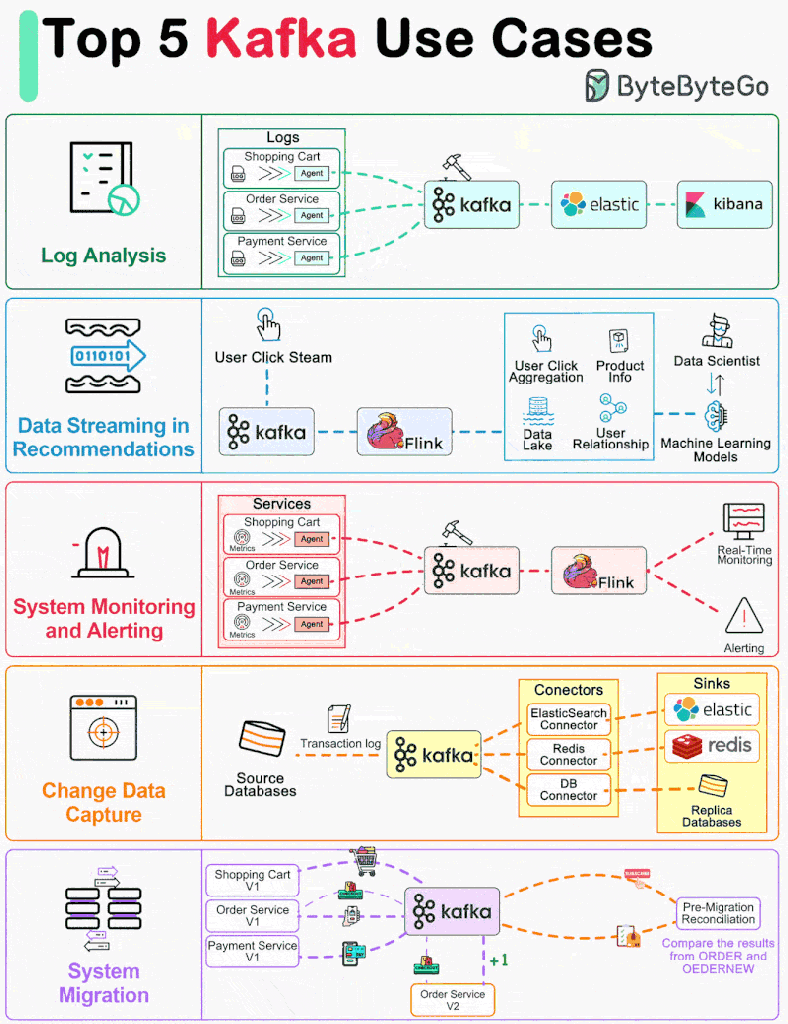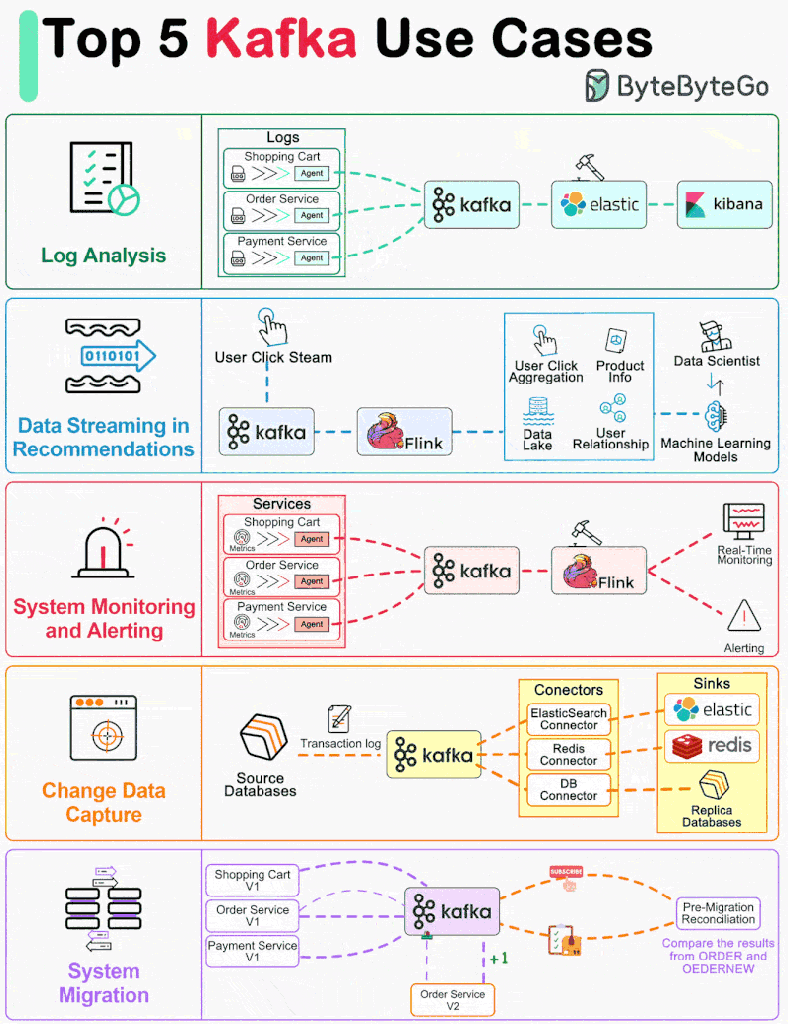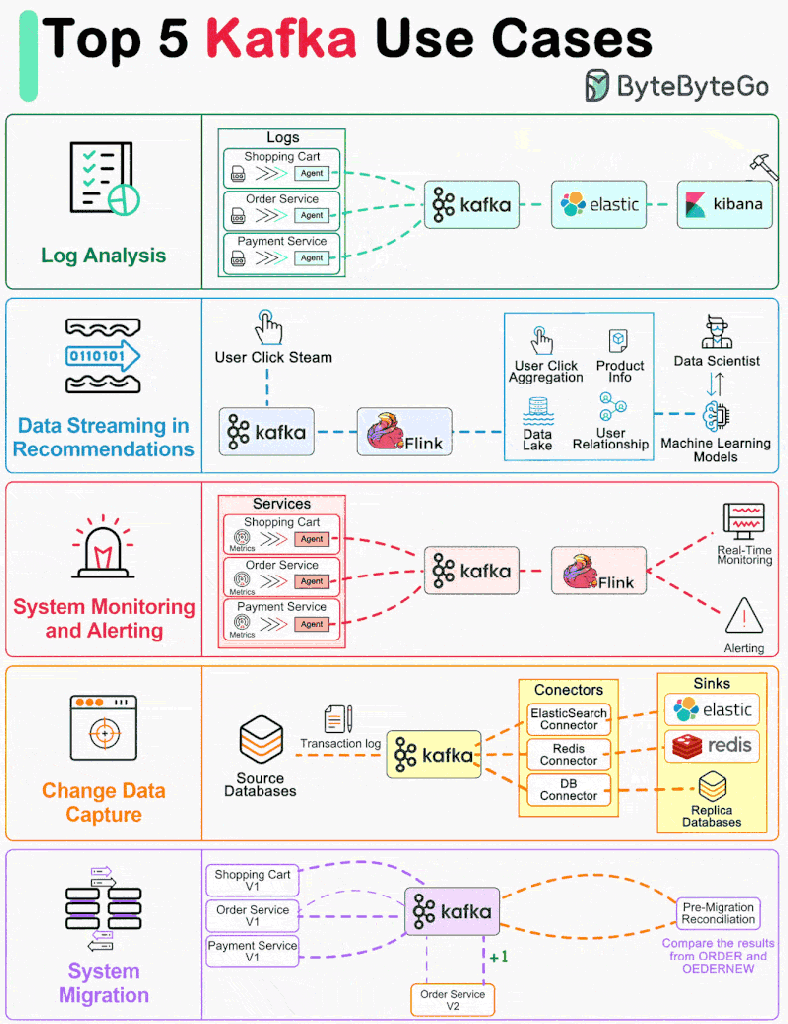
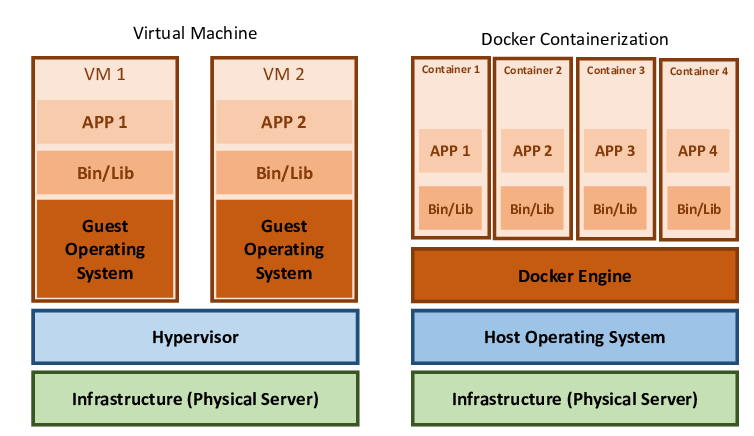
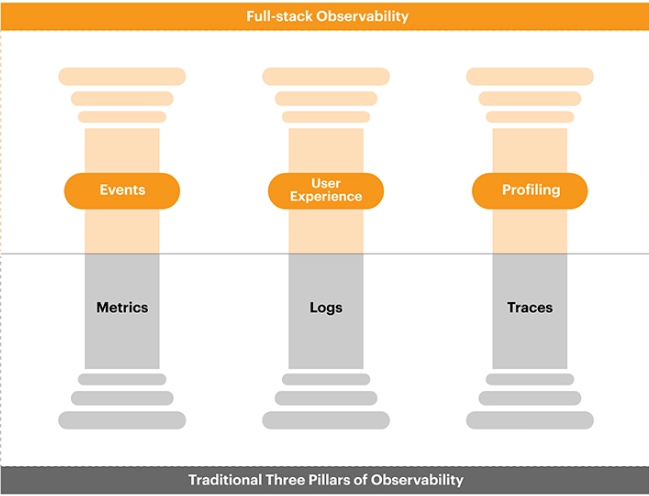
In my previous blog post we talked about the differences in cloud computing and edge computing with respect to data analytics. In this post lets understand the data processing revolutionized via edge computing, what is it? and why is it important?
Edge Computing emerges in the new era as a pivotal player, redefining the paradigm of real-time data processing that can revolutionize the way data is collected, processed and significantly impacting usage across diverse industries. Let’s delve into the depths of Edge Computing to uncover its mechanisms, benefits, applications, and future trends.
1. What is Edge Computing?
Edge computing, a revolutionary distributed computing model, redefines the landscape of data processing by bringing it closer to the source of data generation. Unlike the conventional approach of transmitting data to centralized cloud data centers for processing, edge computing decentralizes the process, positioning it at the “edge” of the network, in close proximity to the devices and sensors collecting data.
At its core, edge computing relies on miniature data centers, often referred to as “edge nodes” or “edge servers,” strategically placed near data sources. These nodes conduct real-time data analysis and processing, leveraging their proximity to data origins to significantly reduce latency and bandwidth usage. This strategic placement not only enables faster response times but also enhances overall system performance.
The decentralized nature of edge computing is a key distinction from traditional cloud computing, as it disperses computational power near the data source, optimizing efficiency. In response to the exponential growth in internet-connected devices, edge computing mitigates the challenges associated with transferring massive data volumes across networks. The conventional method of uploading extensive analytical data to centralized locations can lead to network congestion, impacting critical business tasks like video conferencing in today’s remote work scenarios. Latency, a critical factor for real-time applications, is efficiently managed by deploying storage and servers at the edge, eliminating the need for data to traverse extensive distances.
Edge technology has evolved significantly to address the surge in data generated by IoT devices and the growing demand for real-time applications. By processing data at the extremities of the network, edge computing ensures that only optimized data is transmitted, reducing data transfer times and lowering bandwidth costs. As we witness the continued evolution of technology, edge computing emerges as a transformative force, revolutionizing real-time data processing and offering unparalleled efficiency in the modern digital landscape.
2. How does Edge Computing work?
Edge Computing intricately relies on a distributed architecture that involves deploying micro-data centers or edge servers in close proximity to the data source. This strategic placement brings about real-time data processing capabilities, transforming the dynamics of information handling in the digital era.
Edge Gateways: At the forefront of this transformative technology are Edge Gateways. These gateways serve as the entry points to the edge network, facilitating the seamless flow of data between the local devices and the edge servers. They play a pivotal role in managing the communication and data transfer processes, ensuring that relevant information is efficiently transmitted for processing. Edge Gateways act as the guardians of real-time data, filtering and directing it to the edge servers when necessary.
Edge Storage: Integral to the edge computing infrastructure is Edge Storage, a localized repository for data. Unlike traditional centralized cloud storage, Edge Storage is strategically positioned to house data closer to the point of generation. This proximity not only minimizes latency but also allows for quick access and retrieval of information. Edge Storage acts as a reservoir for the relevant data snippets, ensuring that only essential information is transmitted to the central cloud, optimizing bandwidth usage.
Edge Servers: The backbone of Edge Computing lies in the deployment of Edge Servers. These micro-data centers are strategically scattered to ensure that computational power is readily available near the data source. Edge Servers process data locally, unleashing the potential for real-time analytics and insights. This localized processing minimizes the need for extensive data transmission, contributing to reduced latency and enhanced overall system efficiency. Edge Servers operate in tandem with Edge Gateways and Edge Storage, forming a cohesive ecosystem that revolutionizes data processing dynamics.
In essence, Edge Computing orchestrates a symphony of Edge Gateways, Edge Storage, and Edge Servers to bring about a transformative approach to real-time data processing. This distributed architecture not only minimizes latency but also optimizes bandwidth usage, paving the way for a new era in information handling and digital efficiency.
3. Benefits of Edge Computing
Lower Latency: Edge Computing emerges as a game-changer in the quest for lower latency. By processing data in close proximity to its source, Edge Computing ensures lightning-fast response times. This benefit translates into a profound impact on applications where real-time interactions are paramount. Industries such as gaming, virtual reality, and autonomous vehicles witness a transformative shift, as the latency is reduced to a fraction, enhancing user experiences and operational efficiency.
Improved Resiliency: The distributed architecture of Edge Computing contributes to unparalleled system resiliency. Unlike traditional centralized models, where a failure in one part can disrupt the entire system, Edge Computing decentralizes the processing. This enhances reliability and resilience, particularly in critical sectors like healthcare and finance. In scenarios where downtime is not an option, Edge Computing becomes the backbone of uninterrupted operations.
Enhanced Efficiency: Localized data processing, a hallmark of Edge Computing, brings forth a new era of efficiency. The reduction in massive data transfers minimizes the strain on networks, optimizing overall utilization. Industries relying on resource-intensive applications, such as video streaming and content delivery, witness a surge in operational efficiency. Edge Computing emerges as a catalyst for seamless and resource-effective data handling.
Flexibility & Mobility: Edge Computing shines in its support for mobile and IoT devices, ushering in a realm of flexibility and mobility. Industries that leverage mobile applications and IoT ecosystems, such as logistics and smart cities, experience a paradigm shift. The ability to process data on the edge enhances adaptability, allowing for dynamic and on-the-go data processing. This flexibility becomes a cornerstone for industries navigating the complexities of a mobile-centric landscape.
Reduced Data Transportation Cost: A noteworthy economic advantage of Edge Computing lies in the significant reduction of data transportation costs. Processing data locally minimizes the need for extensive data transfers, translating into substantial savings. Sectors dealing with voluminous data, such as e-commerce and manufacturing, witness a streamlined cost structure. Edge Computing becomes a strategic ally in cost-effective data management.
Real-time Data Processing: In the realm of applications requiring instant decision-making, Edge Computing takes center stage with its facilitation of real-time data processing. Industries like finance, where split-second decisions are pivotal, benefit immensely. Edge Computing ensures that critical data is processed in real-time, eliminating delays and providing a competitive edge in sectors where timing is everything.
4. Types of Edge Computing
Fog Computing: Fog Computing stands as a transformative extension of cloud computing capabilities to the edge of the network. This type of edge computing leverages the power of localized processing, allowing data to be analyzed and acted upon closer to its source. Organizations embracing Fog Computing witness a paradigm shift in efficiency and responsiveness. A noteworthy example is Cisco’s IOx (IoT in a Box) platform, which brings Fog Computing to the forefront. By processing data near IoT devices, it enhances real-time decision-making in various industries, from smart cities to manufacturing.
Mobile Edge Computing (MEC): With a focus on processing tasks on mobile base stations or cellular towers, Mobile Edge Computing (MEC) emerges as a pivotal player in the era of mobile-centric computing. This type of edge computing optimizes the processing of data generated by mobile devices, ensuring swift and localized analysis. An exemplary organization harnessing MEC is AT&T. Through its MEC solutions, AT&T enhances the efficiency of mobile networks, providing faster and more responsive services to users.
Cloudlet: A beacon of localized processing, Cloudlet represents a small-scale cloud data center that extends cloud computing capabilities to the edge. This type of edge computing empowers organizations to establish miniaturized data centers closer to the data source. An illustrative example is Carnegie Mellon University’s Open Cirrus Cloudlet. By deploying cloudlets, the university facilitates edge computing for mobile applications, fostering seamless and efficient data processing.
5. Key Architectural Considerations, Challenges & Opportunities
Security Concerns: One of the paramount considerations in edge computing revolves around ensuring robust data security at the edge. Organizations must safeguard sensitive information as it traverses through distributed architectures. A shining example is Microsoft Azure IoT Edge, which prioritizes security through features like Azure Sphere. With secure-by-design principles, Azure IoT Edge mitigates security risks by implementing hardware-rooted identity and comprehensive threat protection.
Scalability: The challenge of adapting edge infrastructure to varying workloads underscores the importance of scalability. Organizations grapple with the dynamic nature of data processing demands. Amazon Web Services (AWS) addresses this challenge adeptly through AWS IoT Greengrass. By providing a scalable edge computing solution, AWS IoT Greengrass enables seamless adaptation to fluctuating workloads, ensuring optimal performance and resource utilization.
Interoperability: Seamless integration with existing systems is a crucial aspect of edge computing architecture. Achieving interoperability ensures cohesive operations across diverse components. IBM Edge Application Manager exemplifies this by offering a unified platform for managing edge applications. With support for open standards, IBM Edge Application Manager fosters interoperability, allowing organizations to integrate edge computing seamlessly into their existing ecosystems.
Data Governance: Establishing guidelines for data processing and storage forms the bedrock of effective data governance in edge computing. Google Cloud IoT Edge, with its robust data governance capabilities, exemplifies best practices. Through features like Cloud IoT Edge AI, Google Cloud provides organizations with tools to define and enforce data governance policies, ensuring responsible and compliant edge computing practices.
As organizations navigate the edge, addressing these architectural considerations becomes pivotal. By fortifying security, ensuring scalability, fostering interoperability, and implementing robust data governance, organizations pave the way for a resilient and efficient edge computing landscape.
6. Edge Computing in Various Industries
- Agriculture: Precision farming using IoT devices for real-time monitoring.
- Healthcare: Remote patient monitoring and medical data analysis.
- Retail/E-commerce: Personalized shopping experiences and inventory management.
- Automobile/Transportation: Autonomous vehicles and traffic management.
- Manufacturing: Predictive maintenance and quality control.
- Smart Cities: Integrated solutions for energy management, traffic control, and public services.
7. Future Trends
AI Integration: The future of edge computing is intricately linked with the integration of artificial intelligence (AI) algorithms. Organizations are actively exploring ways to enhance decision-making at the edge by infusing AI capabilities. NVIDIA EGX, with its AI-powered edge computing platform, exemplifies this trend. Leveraging technologies like NVIDIA TensorRT, organizations can deploy AI models directly at the edge, enabling intelligent and autonomous decision-making.
5G Integration: As the global rollout of 5G networks accelerates, the integration of edge computing with 5G stands out as a pivotal future trend. The collaboration between edge computing and 5G networks promises faster and more reliable communication. Ericsson Edge Gravity, a 5G-enabled edge computing platform, exemplifies this trend. By harnessing the power of 5G, organizations can achieve ultra-low latency and high-speed data processing at the edge, revolutionizing industries that rely on real-time insights.
Blockchain Integration: Ensuring secure and transparent transactions at the edge is an emerging trend driven by the integration of blockchain technology. IBM Blockchain Transparent Supply, an edge-to-cloud blockchain solution, showcases how organizations can enhance data integrity and security at the edge. By leveraging blockchain, organizations can instill trust in edge computing transactions, particularly in industries like finance, healthcare, and supply chain.
Conclusion
Edge Computing emerges not just as a technological evolution but as a transformative force shaping the future of real-time data processing. The amalgamation of AI, 5G, and blockchain heralds a new era where edge computing becomes not just a solution but a catalyst for innovation. As organizations navigate this dynamic landscape, embracing these future trends, they are poised to unlock unprecedented possibilities. The journey ahead involves not just overcoming challenges but seizing the opportunities that edge computing presents. In conclusion, the era of edge computing is not just on the horizon; it’s unfolding, offering a paradigm shift that redefines how industries leverage data for unparalleled insights and efficiency.