
Kafka, with its robust architecture and scalability, finds extensive use across various industries and applications. (Image courtesy: ByteByteGo)
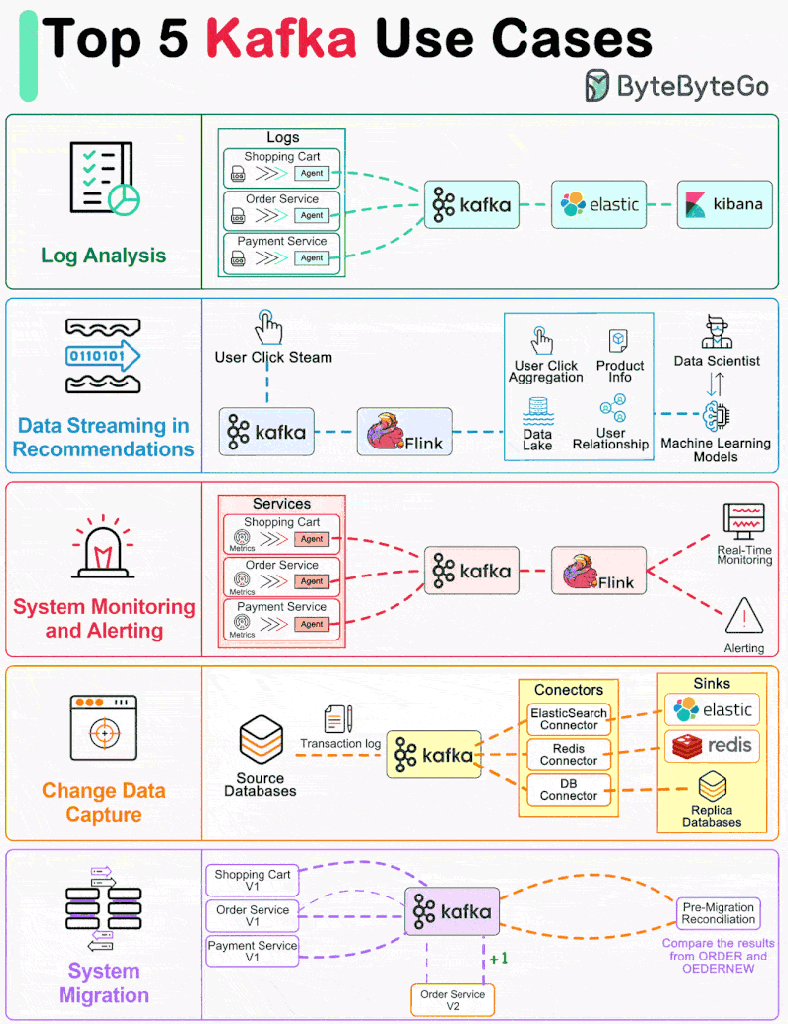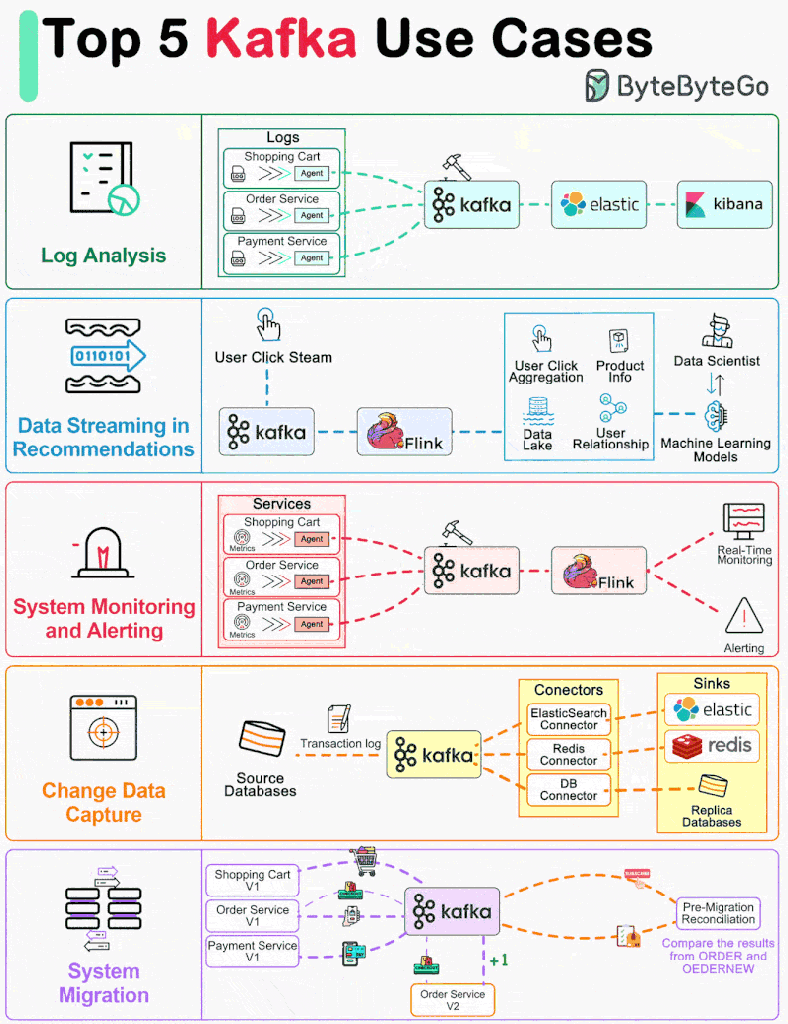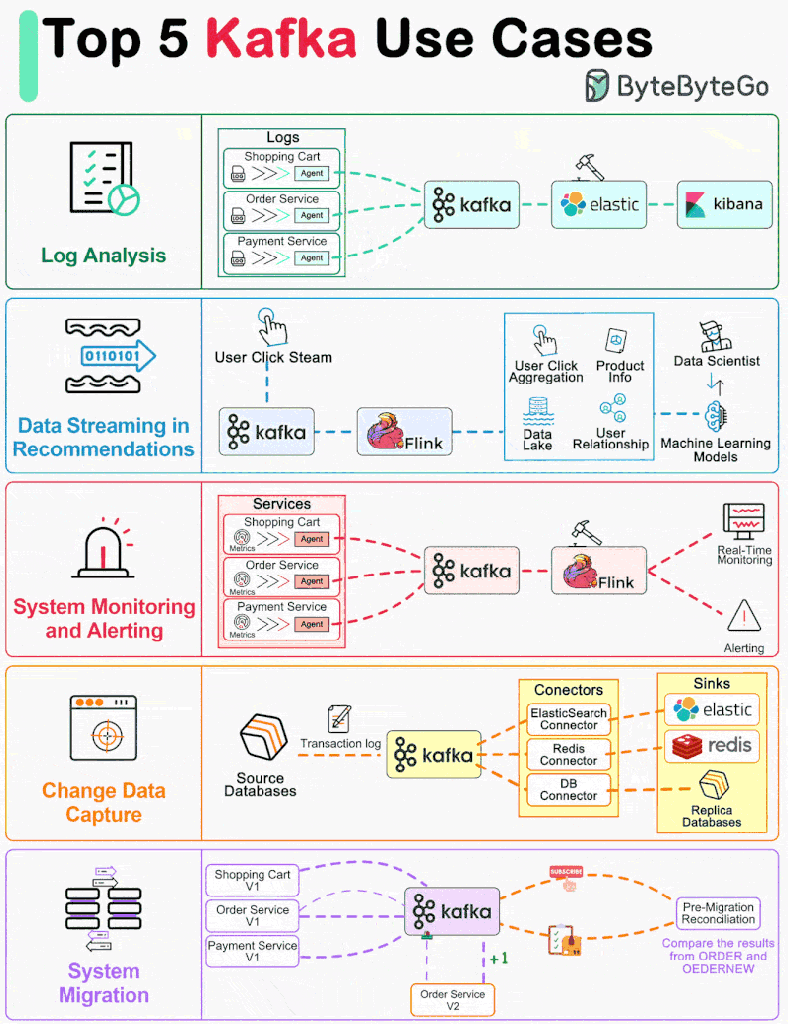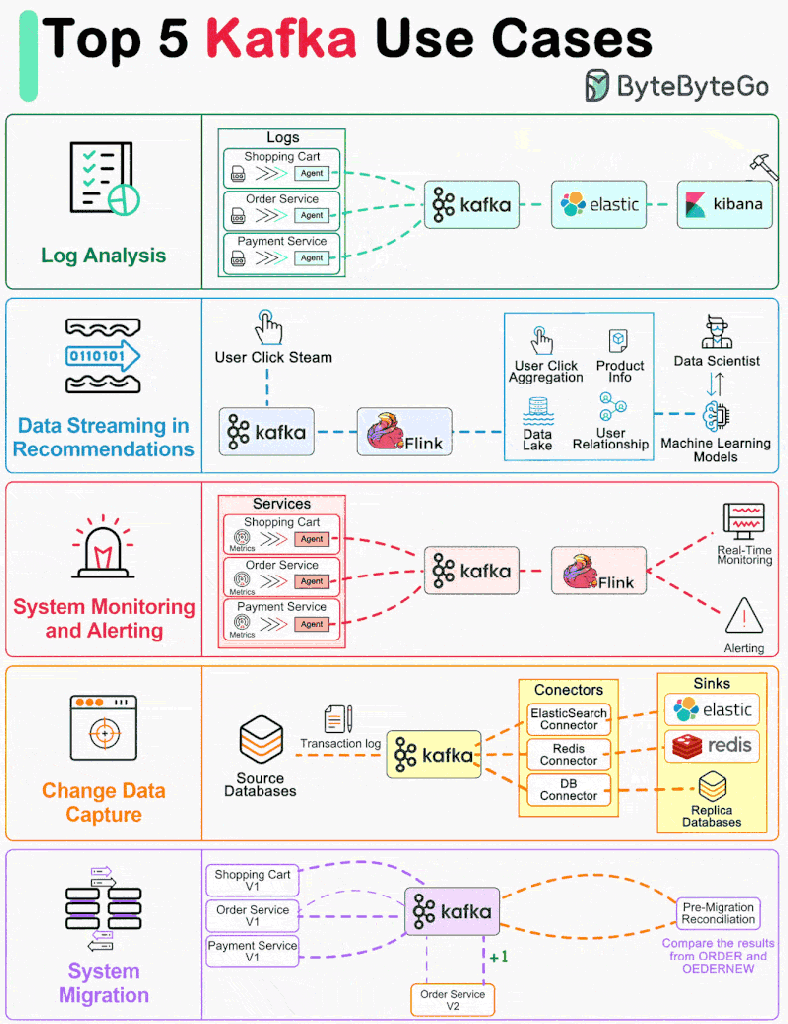
One primary use case is log processing and analysis, where Kafka acts as a central hub for collecting, storing, and analyzing log data from distributed systems. For instance, a large e-commerce platform utilizes Kafka to aggregate log data generated by user interactions, server activities, and application events. This enables real-time analysis of user behavior, system performance, and error detection, facilitating timely decision-making and troubleshooting.
Another prevalent use case for Kafka is data streaming in recommendations systems. Here, Kafka serves as the backbone for streaming user interactions and preferences to recommendation engines. For instance, a media streaming service utilizes Kafka to capture user clicks, views, and preferences in real-time, feeding this data into recommendation algorithms to personalize content recommendations for individual users dynamically.
In addition to log processing and recommendation systems, Kafka is widely employed for system monitoring and alerting. Organizations utilize Kafka to ingest and process monitoring data from various sources, including servers, networks, and applications. This enables proactive monitoring of system health, performance metrics, and anomaly detection, allowing for timely alerts and response to potential issues.
Furthermore, Kafka excels in change data capture (CDC) use cases, where it captures and streams database changes in real-time to downstream systems for analysis or synchronization. For instance, in a retail setting, Kafka captures changes in inventory levels, product prices, and customer orders from the database, enabling real-time analytics, inventory management, and order processing.
Lastly, Kafka facilitates system migration projects by providing a reliable and scalable mechanism for data replication between legacy and modern systems. For example, during a migration from on-premises data centers to cloud environments, Kafka enables seamless data transfer, replication, and synchronization, ensuring minimal downtime and data loss.
Overall, Kafka’s versatility and scalability make it a preferred choice for a wide range of use cases, including log processing, data streaming, monitoring, CDC, and system migration, empowering organizations to build real-time data pipelines and drive insights from their data streams effectively.
